Data Engineering

Profitable Location Data Monetization — 3 Lessons from a Telco Company
Get best practices for turning your organizational data into a lucrative revenue stream, based on actual project experience at a major telco company.

Avoid These 3 Mistakes When Working with a Synapse Dedicated SQL Pool
Learn three often overlooked techniques for optimizing resource utilization and ensuring cost-effectiveness with a Synapse dedicated SQL pool.

Find the Balance between Cloud Cost and Efficiency
Learn how to measure the ROI of a cloud migration and get clarity on the opportunities and challenges inherent in adopting cloud-native solutions.

From Guesswork to Genius: How to Get Maximum Value from Marketing Data and Automation
See how one company used marketing data to learn more about their audience and create more effective campaigns- - and learn how you can do the same.

Data Clean Rooms Demystified: A New Era in Secure Data Analysis
Get up to speed on data clean rooms and find out how they help businesses promote innovation and collaboration while maintaining security and compliance.

My New Favorite Extensions for VSCode: CodeGPT and Github Actions
Make your life as a data engineer easier and more productive with two new VSCode extensions that grant you easy access to ChatGPT and GitHub.

Open Table Formats for Efficient Data Processing: Delta Lake vs Iceberg vs Hudi
Compare three popular open table formats to see which one will give you better performance based on your needs for data storage, processing and more.

Data Fabric vs Data Mesh: Find the Right Fit for Your Organization
Learn the differences between data mesh and data fabric architectures and find out which one's right for your data governance and analytics needs.
MQTT on Steroids: Running EMQX Enterprise on Kubernetes
Learn how to deploy EMQX, a robust MQTT message broker in a Kubernetes cluster with a single command line to leverage its IaC and IIoT capabilities.

IaC 101: Building Reliable Infrastructure with the Power of Code
Learn the basics of infrastructure as code and see tools and techniques that help you get better value and performance from your infrastructure.

Hand-Picked Tools for Building an Open-Source Data Platform
Get open-source alternatives to market-leading tools that will help you build an end-to-end data platform for high performance and cost savings.

Look Out for These Data Engineering Trends in 2023
Learn about the data engineering solutions that will help organizations optimize costs and prepare to tackle the challenges of the coming year.

Ingestions in DBT: How to Load Data from REST APIs with Snowpark
Learn how to transform dbt into a full-fledged ELT solution.

Dagster + Airbyte + dbt: How Software-Defined Assets Change the Way We Orchestrate
See how Dagster changes the game by enabling you to get a simple, singular view of your end-to-end data pipeline across multiple tools.

Extending Airbyte: Creating a Source Connector for Wrike
Find out if Airbyte's claims of outstanding extensibility hold up under scrutiny when building a new connector from scratch for Wrike data.

Advanced Server-side Filtering for Tables in Appsmith
Learn how you can extend no-code with low-code to enable server-side filtering in Appsmith, the open-source alternative to Retool.

Web3 is Lemons — Go Make Lemonade
Learn about blockchain-based technologies and approaches to formulate an effective strategy that will help you take the web3 transition in stride.

Fivetran Acquires HVR: You’re in for a Treat
Find out why Fivetran’s acquisition of HVR with is great news for organizations looking to optimize their data pipelines and streamline operations.

Enabling Scalable Machine Learning in Snowflake Using SQL, Python and Bodo
Most database engines have begun to supplement their SQL capabilities by offering Python query support to allow their more data science inclined users to embed advanced statistics or machine learning code into query pipelines or data visualization tools like Tableau. Snowflake has been bucking that trend — until now.

Testing SQL Pool Performance in Azure Synapse Analytics
The feature set of Synapse Analytics is considerably richer than that of a “plain” old Azure SQL Database, but what benefits do we get from the smallest dedicated pool?

Introducing the Starschema Worldwide Address Data Set in Snowflake
We’re happy to announce that, as part of our ongoing effort to democratize data, we’ve taken over as the provider of The Worldwide Address Data Set, a free and open global address collection on the Snowflake Data Marketplace.
Vaccine Tracking Added to The Starschema COVID-19 Epidemiological Dataset
In our effort to help organizations assess contingency plans and make informed, data-driven decisions in real-time as they respond to the global health emergency, we’ve added vaccine tracking from the University of Oxford to the Starschema COVID-19 Epidemiological Dataset.

StarSnow: HTTP Client for Snowflake SQL
Snowflake is an extremely SQL-friendly database: you can ingest, transform, and access your structured and semi-structured data directly from your SQL code. However, as a cloud-only data platform, it has some fundamental restrictions...
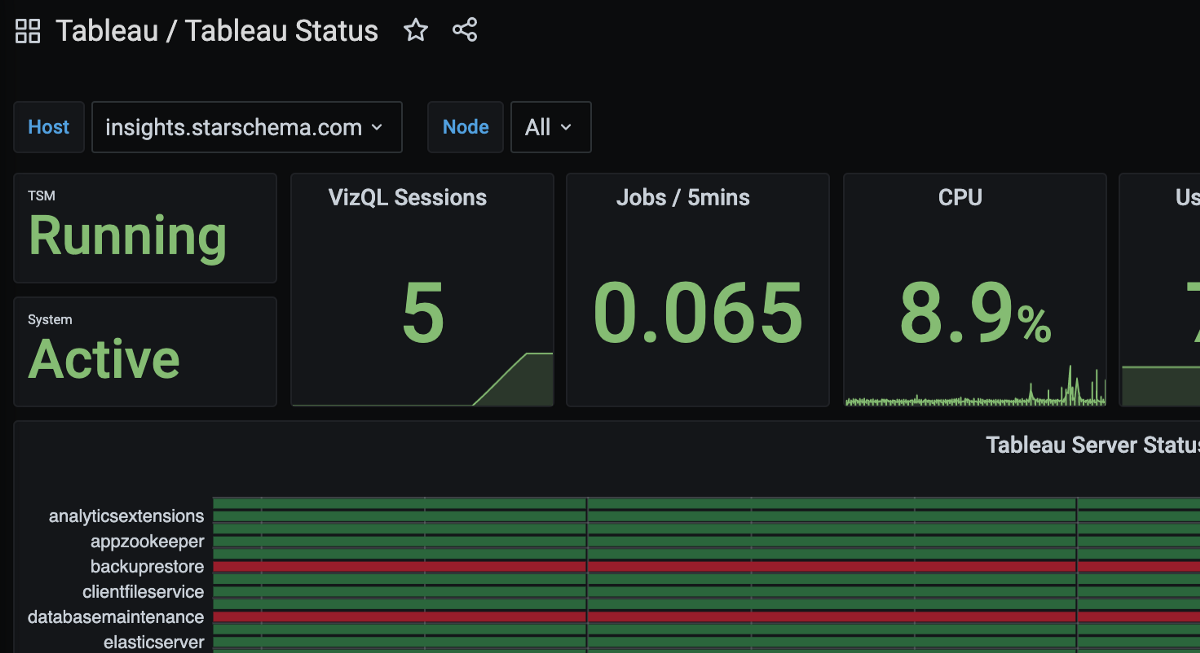
Monitoring with JMX: How to Integrate Tableau Server with InfluxDB
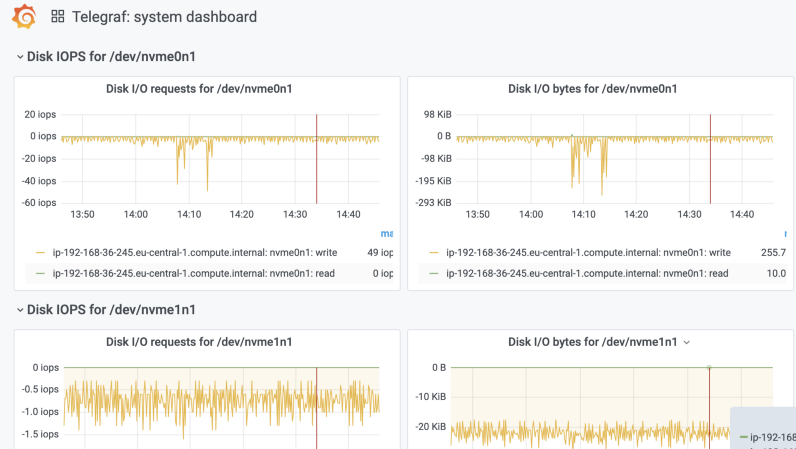
Monitor your infrastructure with InfluxDB and Grafana on Kubernetes
Getting through a challenging age with data - Starschema Blog - Medium

Deploying TabPy in Enterprise: Scaling and Hardening in Kubernetes

Mining your Tableau logs with Apache Drill - Starschema Blog - Medium
